
If you ask most founders or CTOs about their first AI deployment, you’ll hear a surprisingly similar story: the model performed flawlessly in a controlled environment—fast, accurate, efficient. Then, real users arrived. Data tripled. Traffic spiked. Latency crept upward. Cloud costs surged. Suddenly, the same AI system that felt like a breakthrough in testing became an operational burden in production.
This isn’t because the model was wrong.
It’s because the system wasn’t built to scale.
And as adoption accelerates, this problem is becoming universal. According to Gartner, more than 80% of enterprise workloads will involve AI by 2025, while IDC reports that AI compute demand has grown nearly 30x since 2018. McKinsey adds that enterprises who successfully scale AI see 20–30% improvements in operational efficiency.
The opportunity is enormous — but only for organisations that understand how to build AI systems that grow with their business, not against it.
Why AI Scalability Matters for Modern Businesses
AI now powers decision engines, recommendations, forecasting, automation, fraud detection, and entire product experiences. But AI in production behaves differently than AI in a controlled environment.
As usage increases:
- Data becomes messier
- Requests multiply unpredictably
- Retraining frequency increases
- Latency becomes more visible
- Infrastructure costs scale faster than expected
Without a thoughtful architecture, AI becomes slow, fragile, and expensive to operate. That’s why cloud-native design has become the foundation of scalable AI.
Why Cloud-Native Architecture Is Essential-
Trying to scale modern AI without the cloud is like trying to run a global platform on a single local server — technically possible, but painfully inefficient.
Cloud-native AI offers four critical advantages:
- Elastic Compute-Scale GPUs up or down instantly depending on workload.
- Global Performance-Deploy AI endpoints across regions to ensure low latency for users anywhere.
- Built-In Cost Efficiency- Autoscaling, spot instances, and serverless options prevent overspending.
- Faster Innovation – Managed MLOps tools, distributed training, and automated workflows accelerate experimentation.
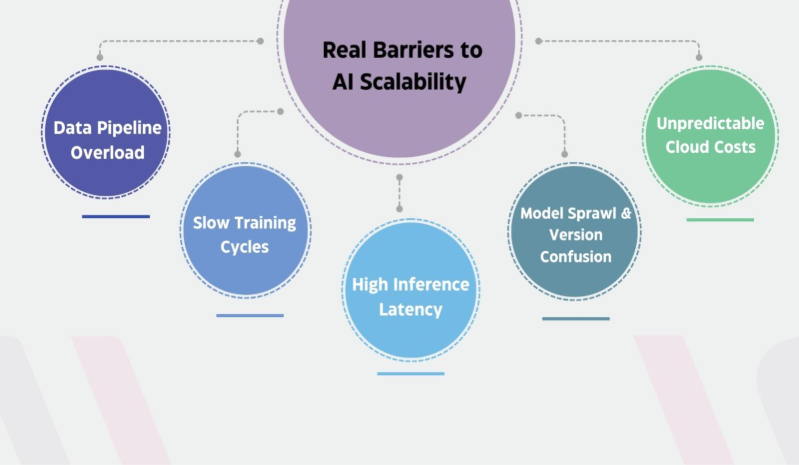
The Real Barriers to AI Scalability — And How to Navigate Them
Scaling AI is not just technical — it’s organisational. Below are the challenges most enterprises face, along with practical solutions.
- Data Pipeline Overload: Pipelines built for early experiments often fail as data volume grows.
Fix: Use cloud-native tools like Kafka, Pub/Sub, Airflow, or dbt with automated validation.
- Slow Training Cycles: Larger datasets make training slow and inefficient.
Fix: Adopt distributed training frameworks (Ray, DeepSpeed, Horovod) and use elastic cloud GPU clusters.
- High Inference Latency: Traffic spikes cause slow predictions and poor user experience.
Fix: Enable autoscaling, GPU pooling, and optimised runtimes like ONNX Runtime or TensorRT.
- Model Sprawl & Version Confusion: Multiple teams and models create chaos without governance.
Fix: Use a model registry such as MLflow, SageMaker, or Vertex AI to manage versions and deployments.
- Unpredictable Cloud Costs: AI workloads can quickly inflate compute and storage expenses.
Fix: Implement cost dashboards, schedule GPU shutdowns, add caching layers, and optimise inference workloads.
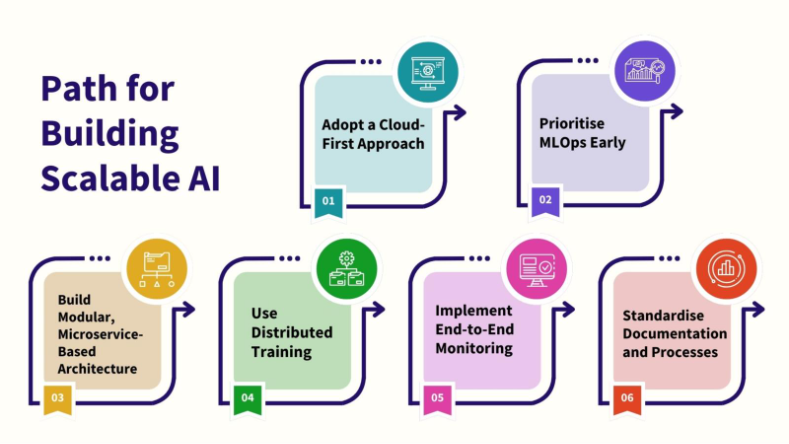
How Companies Can Build Scalable AI–
- Adopt a Cloud-First Approach:
Use cloud-native compute, autoscaling, and managed AI services to support rapid experimentation and growth.
- Prioritise MLOps Early:
Automate training, deployment, validation, and monitoring to eliminate manual bottlenecks as systems expand.
- Build Modular, Microservice-Based Architecture:
Break AI workflows into independent components so each part can scale or update without disrupting the whole system.
- Use Distributed Training:
Leverage frameworks like Ray, DeepSpeed, or Horovod with elastic GPU clusters to speed up model development.
- Implement End-to-End Monitoring:
Track latency, drift, failures, costs, and data quality in real time to maintain reliability and respond quickly.
- Optimise for Accuracy and Efficiency:
Apply pruning, quantisation, batching, and other optimisation techniques to keep models fast and cost-effective.
- Standardise Documentation and Processes:
Use clear conventions, shared guidelines, and organised documentation to improve collaboration and reduce errors.
The Future of Scalable AI Starts Here-
AI’s real value doesn’t come from building a single high-performing model — it comes from building systems that can scale reliably, efficiently, and globally. When cloud-native architecture, MLOps automation, distributed training, and real-time monitoring work together, AI shifts from a fragile prototype into a durable engine for innovation and long-term growth.
This is exactly where Aptlogica accelerates your journey. By designing cloud-native, scalable AI systems — from robust data pipelines and distributed training infrastructure to automated MLOps and cost-optimised inference — Aptlogica helps organisations transform early-stage AI ideas into production-ready systems built for the future.
As AI continues to reshape industries, the companies that invest in scalability today will be the ones defining the market tomorrow.
So the real question is: how soon will your organisation begin building AI systems that are truly ready to scale?
If you’re ready to take the next step, connect with us at sales@aptlogica.com — we’d be happy to help you build what’s next.